As our team’s data science projects’ scope grew, the need for streamlined pipelines and workflows grew. We moved from a collection of ad hoc initiatives to defined projects that require an architectural foundation that could meet their respective requirements.
In this article, I will walk you through some elements related to building our internal ML infrastructure using open source tools like: Spark, Gitlab, Docker and more.
This type of project can be massive in terms of time and effort, so I will only share the necessary elements and features that helped us unwind the most significant bottlenecks in the context our team was working in.
I’ll try to briefly contextualize each bottleneck (from the one causing the most inefficiencies in our context to the least), describe our solution to handle it, and then offer some gain and improvement areas we ended up with at the end of implementing the described solution to the bottleneck in question.
I'll use we to describe me and another data scientist.
Side Note: Our data team had only two data scientists and three data engineers - but I think we managed to do great things even if we were a small team :))
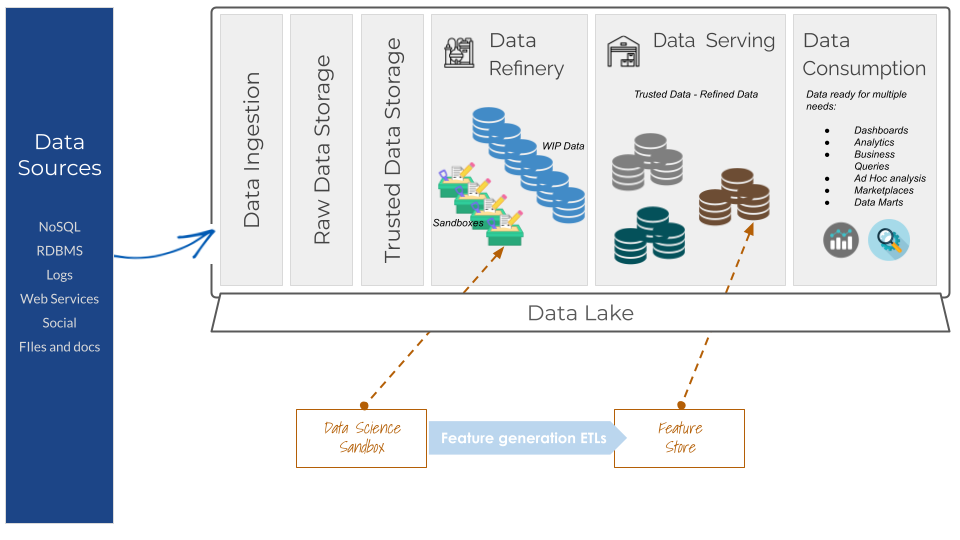
Bottleneck 1: No Streamlined Access to Data for ML
At this point, our team had a data warehouse with mostly clean data. The warehouse was mainly maintained by data engineers.
The first thing we did was work on building a clean and structured feature store.
Gain areas
- Ready to use features
- Faster than before experimentation cycles
Improvement areas
- Using CSVs or JSON to move data
- Need for specific loading pipelines for each ML project iteration
- Show data extraction and loading
We then re-architected some zones around the in-place data lake in order to ease data access for tools like Rstudio, Jupyter Notebooks, Tableau and PowerBI. This helped us save a lot of time and avoid loading multiple files because of a needed alteration (needing a new feature, data sampling…etc)
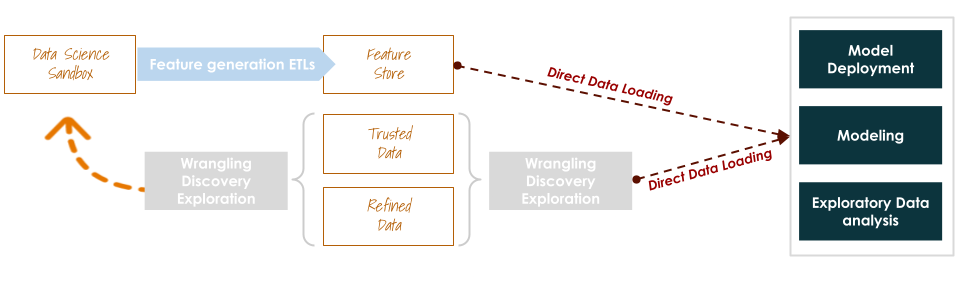
Gain areas
- Near full automated ready-to-use parameterize-able features
- Better data bandwidths
- Faster than before experimentation cycles
- Data preparation and featurization both owned by data scientists, but could be easily collaborated on by data engineers (huge contextual gain, given that we were a small team)
Improvement areas
- Data scientists are now more involved in data quality assessments (came with new responsibility and ownership of new data preparation and featurization pipelines)
Bottleneck 2: Dev vs Prod environments are not defined and managed
Even though we now had a better data management environment, our experimentation and deployment environments were still not defined and managed; which made collaborations, follow-ups, monitoring, …etc very difficult.
Our designed solution to this bottleneck needs to be able to integrate a double perspective, namely the dev perspective and the production perspective.
Dev perspective
Questions led
interactive
ad hoc, post hoc
Changing data
Speed and agility
Prod perspective
Measures lead
Automated
Systemic
Fixed data
Transparency and reliability
Our infrastructure will be deployed using Docker, to ensure that it’s portable and duplicable. This, below, is what it looked like at the end of its first major release:
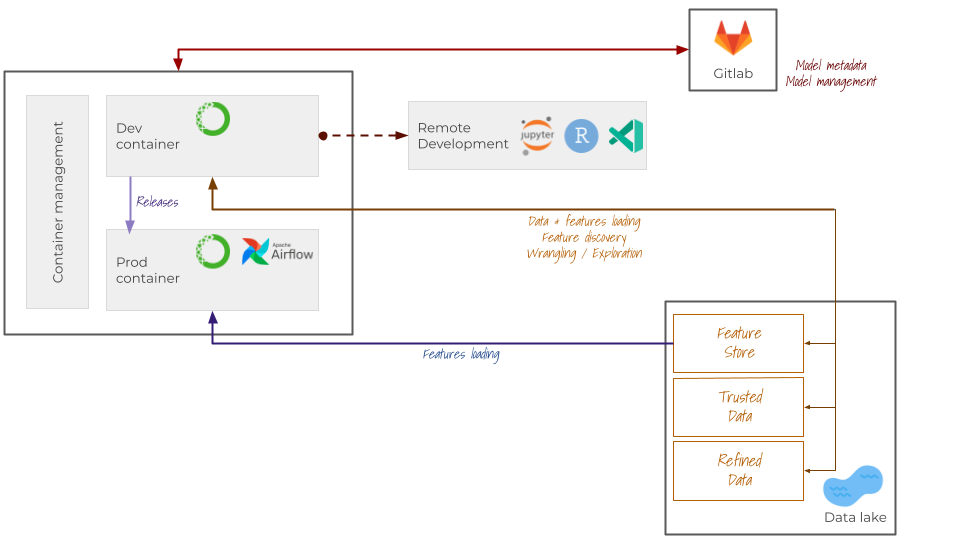
Gain areas
- Portable infrastructure
- Modular, decoupled and versioned infrastructure
- Managed and reviewed code
Improvement areas
- Model management needs a more modular area of management
- Model Tracking experiments only using files metadata
Bottleneck 3: No managed centralised repository for our code base
We initiated a project to structure our scattered pieces of code and to develop new or reworked pieces of code that we needed during experimentation and deployment.
This project consisted of 5 channels that we worked on iteratively:
- Bring together all the pieces of code into one place that met the requirements of duplicity, frequent usage, functionality
- Sift through the pieces of code and filter out duplicates
- Build a parametrable data movement toolkit to streamline data accessibility at all points of entry
- Build an experimentation/dev library containing functions that are frequently needed during experimentation
- Build a deployment/prod library containing functions that are specific to each deployed project following a structure we decided on (and best practices sourced from shared open source project published on github - like Sklearn)
Before continuing to the solution, I’d like to emphasize why iterative development on this project was a - if not the - key to its success: it made it possible for us to process chunks of code and see where they can efficiently fit. This allowed us to have a very flexible code architecture - meaning that nothing is really fixed until it’s assessed with varying degrees of scrutiny (which eventually led to minimizing technical debt.)
Another major advantage to working iteratively on this project was having the possibility of operating finished chunks or modules, instead of waiting until everything is operational.
Additionally, risks can be identified in parallel during each iteration and can be dealt with as a high priority immediately.
Back to the solution !
After closing the first major release of our project, our ML platform looked like the image shown below.

Gain areas
- Managed and reviewed code
- Tested code units
Improvement areas
- More testing and quality assurance

Feature store
Some code snippets to build various types of feature generators are shared on my GitHub. Clone the project to play with the code and add other generators that fit your needs.
Access the repository
Digital notebook
A pipeline break-down of feature generation and engineering is also shared on my digital notebook. I added an illustration of the system and structure to demonstrate the flow of the data value chain associated with a project like this.
Discover moreCitation
Please cite this article as :
NNZ. (June 2022). How We Built Our Own ML Infrastructure. NonNeutralZero.https://www.nonneutralzero.com/blog/engineering-7/how-we-built-our-own-ml-infrastructure-11/.
or